
Throughout history, civilizations have ingeniously engineered systems to ensure clean water and sanitation. From the Neolithic period to our modern era, the design and construction of aqueducts have evolved significantly. The Roman Empire is a testament to the triumph of engineering, as it conquered valleys and cities to deliver water to its urban centres and fields.
To what extend is data like water?
In our modern world, access to clean water is widespread, but now, access to clean data is equally vital for survival. Organizations cannot thrive without data, which permeates every aspect of our lives. When data becomes inaccessible, it is left to waste. This situation underscores the critical importance of effective data management.
Data is akin to water – it requires ongoing cleaning to prevent contamination. Just as water is cleaned for various purposes, personal data must be thoroughly cleaned for analysis while complying with data protection laws. Both water and data must meet quality standards suitable for their intended purpose.
We are aware that animals and humans can drown in water. Nowadays, we can all drown in data. Too much data can paralyze and overwhelm us. Appropriately sized data is data that anyone can transform and process into usable forms promptly – well-packaged data can be used again. The latter requires lower resources.
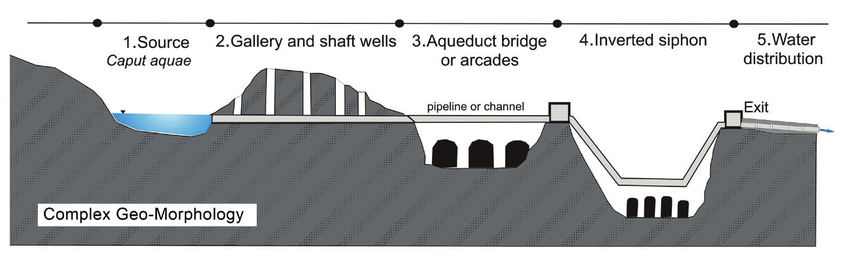
To what extend is an aquadect like a data architecture?
A Roman aqueduct illustrates how the water travels from its source across montains and on top of bridges, using pipelines and inverted siphons. The design of the aqueduct applied technologies using gravitational forces to keep the wather moving, waterwheels and zigzags to remove as many impurities as possible. The Romans had strong civil duties to bring clean water to cities and support farming.
This engineering marvel would have required a whole team and a wide range of skills.
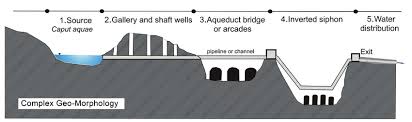
A typical Roman Aqueduct 1
A real-asset tracking and management data architecture would capture data from trackers (IoT), before ingesting the operational data and transforming it into a format that can inform its users in real time of their assets. Impurities are also reduced through the transformation.
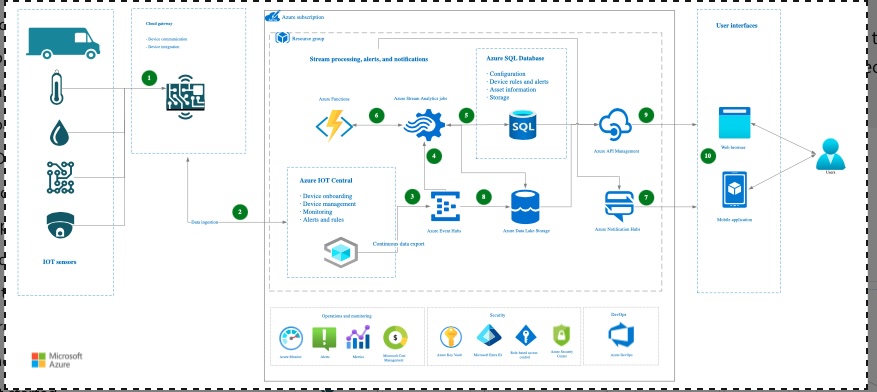
Managing water and data takes energy resources, and it requires time, investment, and innovation. Both water and data rely on pipelines and infrastructures for transportation, transformation, and consumption; aqueducts and data infrastructures share some similarities – the content is different. With a well-defined strategy, aqueducts and data infrastructure are likely to add values – meeting business needs through continuous improvement, creative problem-solving, and design processes.
Questioning is everything
Questioning everything from start to finish of the problem-solving cycle can be beneficial. Questions can guide us in finding solutions that may suit the users’ needs at a certain point in time.
- What is the problem?
- How will we know we have solved the problem?
- What are the alternative options we may have to solve the problem?
- Which solution is likely to meet best the users’ needs?
- To what extent have we solved the problem? Why?
- What have we learnt?
Questioning whether a problem is well-defined is worth it. Without any design problem, we may not think in a design way. Design thinking encourages a systemic approach that can stop working in siloes. Questioning a problem can avoid creating an artificial problem to play with some technology or new scientific development without clear justification. Instead, design thinking can bring multi-disciplinary team to engage with a user-centred approach
A technological approach would bring together (1) relational databases with a front end and (2) some GDPR compliant authorisation for authentication and authorisation. Without considering which data is critical, how the data will be used the data warehouse system could become a burden. A business needs to use data would need bring some use and added value. Some design questions should lead understanding the problem domain should be the starting point. So, perhaps the following questions needs to be asked:
- How can we consolidate data from various databases to support strategic decision making?
- How can we transform satelite images to identify and catalogue trees around the world?
- How can we conduct an individual-level data analysis without sharing the data?
- How can we comprehend and evaluate automated generated algorithms?
The easy and easier option is to “solutionise”. I have recently witnessed someone making the statement we do not know the problem yet, but I know what the solution is.
Well the solution was to use an Object Relational Model system (ORM) with low-code options. The rest of the project was to prove or disprove the proposed solution was the best way forward. We had to explore and learn how data was stored and question its suitability, as a data architecture. We had to argue and discover potential security issues brought the integration with existing eco-system. We had to argue whether the type of data storage – a simplified relational data management system – would really support the specialised data. We had to argue and demonstrate the burden brought to transform potential operational data into analytical one into the organisation data warehouse system. We had to learn about the problem and its domain.
In another instance, the problem was known but we had to work under very tight deadlines. We considered to start from the absolute beginning, which was not an option. Inevitably, we catalogue existing solutions that were close to the problem and explore the extend of their suitability. We discovered some operational and analytical data model could be used again across several solutions. We worked closely with the user-interaction and services designers to validate the hypotheses. We discover documenting and communicating the findings was lowering barriers to comprehension from a wider audience. The wider community could identify already known patterns.
Exploring alternatives can also prevent negative impact brought by changes made to some operational model. Self-referencing in relational database can bring some real scalabilities issues. Such model was proposed by a developing team to meet new needs. We proposed a fuzzy method to self-referencing – i.e., use of a many-to-many relationship with temporal data. We also considered using a graph database to process such data and relationship. Knowledge graphs were considered too. The impact on the analytical data model was explored with some actions to preserve data quality applied as much as possible to reduce impact.
We may be applying mathematical, scientific and other conceptual concepts with the help of technology and science. Both evolves so fast and evolving new needs all the time. Data Warehouse arisen at the end of the last millennium, but the idea is being implemented and improved all the time. In 2024, the use of AI securely to transform data into knowledge and knowledge into wisdom continues to lead.
At the start of the millennium, a data architecture for an international company was created to explore how operational data could be shared more effectively from around the world. The Internet capability somehow brought some interesting challenges. Nonetheless, we were able to map how data flow against business activities. This work led to simplification and optimisation of the workflow. Also, there were this thirst of having access to analytical data for decision making. It was interesting how the data was planned and designed to start reporting on the senior management needs.
Not all the users’ needs direct access to the data. Sometimes, some aggregations, statistical results or predictions are enough. S.A.F. E.S.T is a conceptual data architecture – based on the DataShield model – that is technology agnostic. The idea of relying on an hub-and-spoke architecture simplifies the network communication. The federation of data sources – through strict data governance and FAIR principles – can only support researchers without transferring physically data. Datasets are getting larger and use of personal data is protected by the law. Therefore, ethical and practical solutions is likely to meet best contemporary users’ needs.
Users need more and more high quality data to support application of advanced statistical methodologies and machine learning algorithms. The government data quality framework can help supporting identifying critical data that supports the users’ specific needs. Some of those needs support operational users, but some others analytical users too. Therefore, cataloguing operational data, identifying unique identifiers for merging datasets based on real-life objects has been useful. The technology may change and users need evolve to adapt to new opportunities. However, good quality data remain the backbone to any solutions that can meet the users’ needs.
Innovate and add value
Data is a precious thing and will last longer than the systemsthemselves.
Tim Berners-Lee
Water is critical for sustainable development, including environmental integrity and the alleviation of poverty and hunger, and is indispensable for human health and well-being.”
United Nations
Innovation and adding value should guide any endeavour. Definining problems and trying to find innovative solutions should be a priority and ways of working. Measuring the value in term of quality of life, health, and financial well-being should indicate whether we are succeeding or failing. Measuring how water is managed to sustain life relies on good use of data.

