Our early school years involve a lot of remembering, recognising facts , terms, or basic concepts without really understanding them. We often receive a lot of facts, terms, basic concepts and we find ways to remembering and recognising,. For example, Jack Skellington is reciting carols, remembering every fact he can find about Christmas, yet he lacks of understanding., but he has gained some knowledge. He has made some associations.
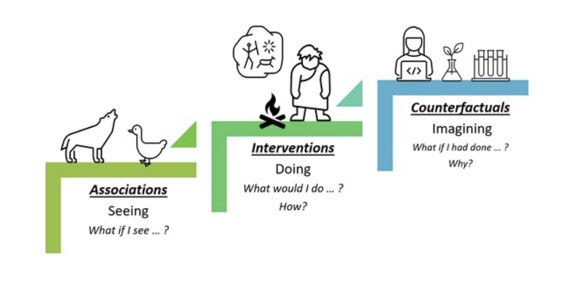
Like Jack we start learning by establishing facts,terms, basic concepts.. The skeleton leading Halloween linked the idea that a present is a box containing a toy, unknown to the person who receives it. However, adding the cultural ghoulish and scary part demonstrated a misunderstanding. He starts doing, moving on an intervention phase. The latter illustrates, knowledge to develop some comprehension, application, analysis, synthesis and evaluation. Those latter phase can let us acknowledge our error and not repeating them.

Knowledge becomes our base and foundation to grow and develop skills. For that reason, Educators have perceived Bloom’s taxonomy as a significant model to represent learning. And development of skills. The taxonomy succeeded to bring a more cohesive approach to education – especially a common tool to lower the gap between educators, the design of curricula and examinations. It now guides educators tailoring learning activities in and out of the class room too.
The research community has explored ways to use computer science for the purpose of understanding better human cognition and problem solving. Newell and other researchers aimed at simulated intelligence, to solve problems. Their work contributed to the use of genetic programming for generating solvers of NP-hard and mathematical problems. Other focused on modelling knowledge using a data structure.
Storing is not knowledge
Data structure suggests may be grouped in a linear manner, in its simple form. Non-linear form also allows storing, organising data in more complex manner. Relational databases rely on columns an rows to represent grouped data as a set to avoid storing storing redundancies. Object-oriented database integrates operations stores characteristics of real life objects with operations attached to them. Both originated from research in the 1970s. Relational database became more popular, but today object-oriented database is referred as document-database. The latter can be suitably used for data analytics and science purposes.

Tree data structure are often simulated using network database; a relational database designed with some relationship pointing to the same entity; table once implemented in a data dictionary. Network database can also be expanded in graphs for visualisation purposes.
Graph is also a common data structure used in computer science. Based on directed graphs, a mathematical concept composed of connected pairs of elements using vertices and arcs. Neo4J appears to transform networked database into directed graphs.
So far we have assumed that this data is organised and structured. We have yet considered unstructured and semi-structured data, which are hidden in multi-media content. The latter may include documents, video, audio content – this list is not exhaustive.
The need of Describing resources
Storing data are considered as fact, to become knowledge it must be processed and transformed. Traditionally, we applied descriptive statistics, and graphical representation. More recently we started to apply advanced statistical and probabilistic methodologies, including machine learning techniques. Those techniques automate the transformation of data into knowledge, but are there any alternatives.
Imagine a physical library, before. the digitalisation age, without any sections, catalogue, or any organisations. It would pretty challenging finding and identifying a specific book. The act of curating this data about library books can be perceived as meaningless without a service to provide and motivation. Without a description, any books become undervalued. Therefore, it becomes essential any books should be described. Incidently, all this organisation may be affecting librarians in other part of their life.

As the popularity of the World Wide Web rose exponentially, a substantial amount of content stored in textual, audio, and other multimedia content grew exponentially too. Tim Berners-Lee created a universe of information without any catalogue and description. An extension of WWW was, therefore, proposed using unique references identifier to build a global database. The resources description framework aimed at both curating unstructured data and offering a means to interlink disparate data together. The unstructured data would therefore become consumable by machines and humans.

Data is encoded as subject, predicate, and object. Each value of the triple should be an URI. The predicate is often a verb, but the subject and the object can support data linkage from different sources. The latter occurs when the same URI can be matched. We could, therefore, visualise a collection of triples in a directed graph. The vertices becomes the subjects and nodes – the predicates the edges. Directed graphs are mathematical concepts that are encoded in many various way; i.e., matrices, tuples, dictionary, list of integers, the list is not exhaustive. The author acknowledges many practitioners interchangeably refers to graph databases, RDF, and knowledge graph. RDF is one possible implementation.
These triples remain meaningless if the properties and relationship between the data remains undefined. Consequently, some meaning and semantic is added through ontologies. Subjects and objects are defined as classes, with properties and predicates. The latter is specific to the domain. Therefore, Jack may create an ontology suggesting a present is a thing and a subclass of a box. He may defines a toy as a thing too and a present contains a toy. A toy may have a name that is a character value.

Data curation: human or machine?
Human curated data appears to support a high level of granularity. For example, we created an ontology and some RDFs (see below) based on the Titanic dataset. Creating the ontology deepened the understanding of the data and what it represents.
The author noticed the culture at the time of the concept of a family was a lot different than nowadays. The author was able to add some additional links other datasources – adding other dimensions. It was good to discover more about cabins and their locations on the boat itself. The author had to stop herself spending time in her research – other things to do, sadly. The point is that some opportunities were opened.
The author also relied on established modelling techniques such as Dublin core or schema.org. The act of human curation has added some knowledge gain – the one only a librarian is likely to have. To be honest, a lot more than the author expected and ever wanted to know about the Titanic.
Ontology : titanic_ontology.xml
RDFs : titanic resources description framework.
Some form of AI – machine learning – was also used to learn interesting pattern about the titanic. We exposed and rediscovered disturbing patterns such as the passenger class increased the chance of surviving the accident. In some cases, perhaps, prioritised male passengers instead of women and children. At the time, the latter had priorities on life boats. We learnt too that many advanced statistical methodologies may have learnt some bias based on class and gender too. The data is far too complex to find a general model for that.
ML : Data preparation and application of machile learning techniques
The transformation of the Titanic dataset into RDFs and into a format machine learning (advanced statistical methodologies) was time consuming. Storing the RDFs and ontology would require a lot more storage than a relational database. However, Wikidata.org appears to be highly successful example of applying those principle. Transforming data for human curation and machine curation requires a lot of specialised skills based on mathematical, computing, scalability of computing. It was an adventure to go through those transformation. It would be worse to explore further how it impacts on our ways of working too.
A combination of RDFs, ontologies, and automating the learning has supported well gaining some understanding, knowledge about the Titanic. In both cases a lot of transformation of the data was required leading to developing skills, knowledge, and augmenting intelligence.

A bit like Jack, the author is not a ship builder or any other engineering subjects that has helped to build the Titanic or take the decision whether she should have sailed. Jack has learnt a bit about Christmas and reach the counter factual stage. Perhaps Jack has curated all his resources and finding to avoid next generations of Halloween residents making another attempt.

With the rise of large language models, such as chatGPT, we could all get tempted to rely on such tools to create content, write university assignment, prepare tutorials, or marketing content. It could be tempting to trust blindly the produced content. Instead it can augment our knowledge. It could augment our intelligence if we and only if, we can explain the method of learning, justify the learning metrics and communicate it to its users.
Well, Jack was unable to recreate Christmas from a little knowledge, what will we do with all this automation of learning and curation of data?

